адаптированный перевод статьи Rachel Lea Ballantyne Draelos, Мау 5, 2019
Как само-управляемые машины распознают дорожные знаки? Как Facebook автоматически отмечает вас на фотографии? Как компьютер достигает уровня дерматолога при классификации кожных заболеваний ?
Во всех этих приложениях компьютер должен «видеть» мир: он принимает числовое представление электромагнитного излучения (например, фотографию) и вычисляет, что означает это излучение.
Компьютерное зрение – это широкая область, в которой сочетаются искусственный интеллект, инженерия, обработка сигналов и другие методы, позволяющие компьютерам «видеть». Сверточная нейронная сеть («CNN») является одной из моделей компьютерного зрения.
За последние несколько лет популярность CNN возросла благодаря их отличной работе над многими полезными задачами. CNN используются для всех приложений компьютерного зрения, описанных в первом параграфе, от маркировки фотографии до интерпретации медицинских изображений. В этом посте будет рассказано, как CNN позволяют создавать много интересных современных приложений для компьютерного зрения.
Ссылки
Входные данные CNN: как изображения представлены в компьютере
Входные данные CNN для приложений компьютерного зрения – изображение или видео. (CNN также могут быть использованы для текста, но мы оставим это для другого поста.)
В компьютерах изображение представляется в виде сетки значений пикселей, то есть сетки положительных целых чисел. Вот простой пример, где цвет пикселя «белый» представлен 0, желтый – 2, а черный – 9. (Для простоты визуализации цвета по-прежнему отображаются в показанном изображении, хотя в на компьютере сохраняются только цифры):
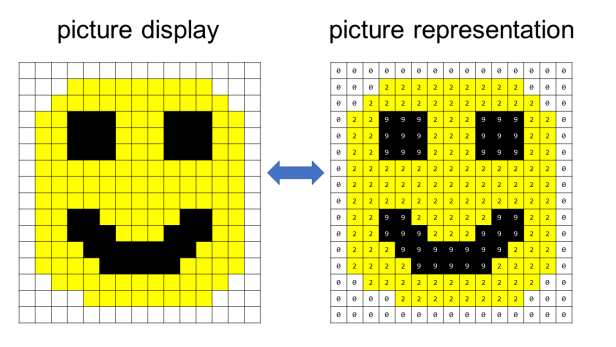
На практике цветные изображения представлены тремя сетками чисел, сложенными друг с другом: одна сетка для красного, одна сетка для зеленого и одна сетка для синего. Элементы каждой сетки определяют интенсивность красного, зеленого или синего цвета для каждого пикселя, используя число от 0 до 255. Для получения дополнительной информации о том, как представлены цветные изображения, см. цветовую модель RGB.
В оставшейся части этого поста мы будем использовать упрощенный пример смайлика, показанный выше.
Выходные данные CNN
Выход CNN зависит от задачи. Вот некоторые примеры входов и выходов CNN для различных задач классификации:
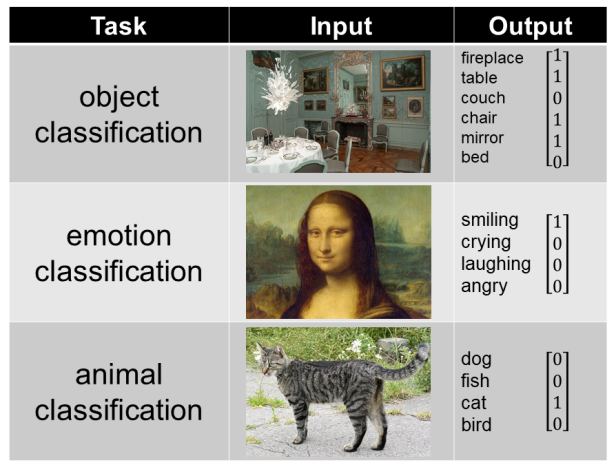
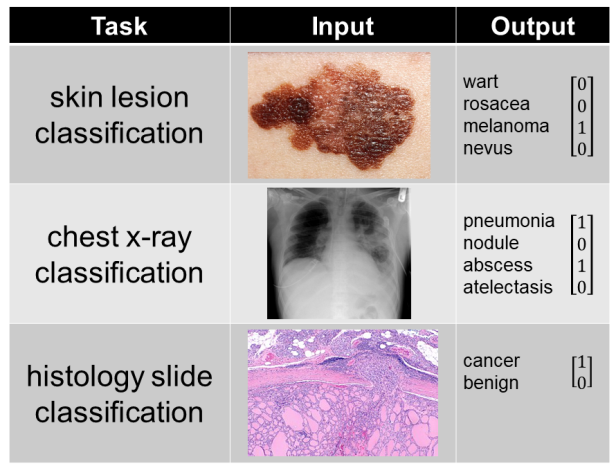
Исходные изображения: blue dining room, Mona Lisa, cat, melanoma, chest x-ray, follicular thyroid carcinoma
При обучении CNN для любой задачи требуется много обучающих примеров. Например, если бы вы обучали CNN классификации животных, вам понадобился бы набор данных из тысяч изображений животных, где каждое изображение соединено с двоичным вектором, указывающим, какие животные присутствуют на этих изображениях. Для получения дополнительной информации об обучении и тестировании нейронных сетей, смотрите этот пост.
Основная идея
В CNN различные «фильтры» (маленькие сетки чисел) скользят по всему изображению, осуществляя операцию свертки. Различные фильтры с разными числами будут обнаруживать различные аспекты изображения, например, горизонтальные или вертикальные края. В CNN используются много разных фильтров, чтобы идентифицировать разнообразные аспекты изображения.
Эта анимация показывает фильтр 2 x 2, скользящий по верхней части изображения смайлика:

Составляющие CNN
Подобно нейронной сети с прямой связью, CNN состоит из «слоев».
Один слой в CNN включает в себя три вида вычислений:
- Свертка: это сердце CNN. Операция свертки использует только сложение и умножение. Сверточные фильтры сканируют изображение, выполняя операцию свертки.
Активация: это нелинейная функция, применяемая к выходу сверточного фильтра. Добавление нелинейности позволяют CNN изучать более сложные отношения (кривые вместо линий) между входным изображением и выходным классом.
Объединение в пул: это часто «максимальное объединение», которое просто выбирает наибольшее число из небольшого пакета чисел. Объединение в пул уменьшает размер изображения, тем самым уменьшая объем необходимых вычислений и делая CNN более эффективным.
Эти три вида вычислений – свертка, активация (нелинейность) и объединение – используются для построения «сверточной» части модели CNN. CNN, которая использует только эти операции для получения окончательных предсказаний, называется «полностью сверточной сетью». В отличие от CNN, которая использует полностью соединенные слои после сверточной части (полностью соединенные слои являются строительными блоками нейронные сети с прямой связью).
Как “обучается”
CNN – это своего рода алгоритм машинного обучения. Как именно обучается CNN?
Алгоритм изучает, какие значения использовать внутри сверточных фильтров, чтобы предсказать желаемые результаты. Фильтры, содержащие разные значения, обнаруживают разные характеристики изображения. Мы не хотим сообщать модели, какие характеристики нужно искать, чтобы определить, есть ли кошка на картинке; модель самостоятельно решает, какие значения выбрать в каждом из фильтров, чтобы найти кошку.
Если в конце есть полностью соединенные слои, CNN также обучится, какие значения использовать в полностью соединенных слоях.
Сверточный фильтр
Фильтр CNN – это квадратная сетка чисел. Размеры фильтра указываются при сборке CNN. Некоторые обычно используемые размеры фильтров: 2 x 2, 3 x 3 и 5 x 5, но они могут быть любого размера по вашему выбору.
Когда CNN инициализируется, еще до того, как произошло какое-либо обучение, все значения для фильтров определяют случайными числами. В процессе обучения CNN настраивает значения в фильтрах таким образом, чтобы фильтры определяли значимые характеристики изображений. Вот несколько примеров сверточных фильтров разных размеров, которые были инициализированы случайными числами:
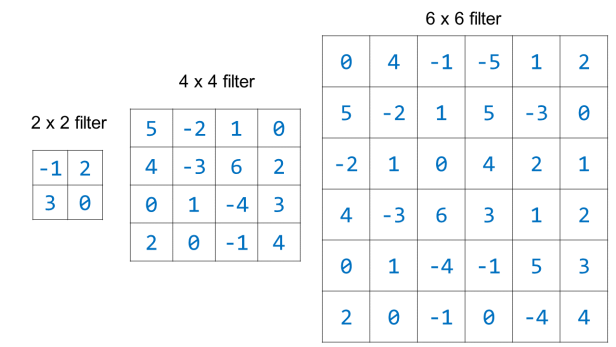
Обратите внимание, что на практике числа, выбранные для случайной инициализации, будут меньше, и они не все будут целыми числами (например, случайно инициализированные значения фильтра могут быть -0,045, 0,234, -1,10 и т. д.).
Сверточная операция
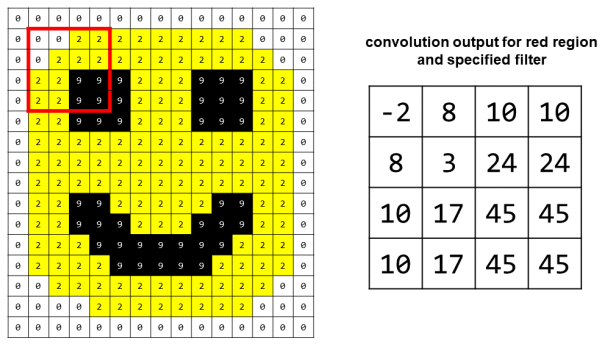
Вот как работает свертка. Давайте возьмем крошечный фрагмент изображения смайлика и применим к нему свертку, используя фильтр 2 x 2 со значениями (1, 2, 3 и -1):
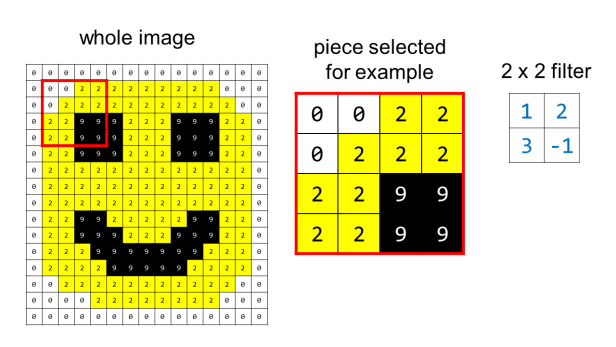
Для примера рассмотрим:
- Фильтр, который мы используем, приведен синим шрифтом слева для справки.
- Раздел 2 x 2 изображения, который свернут с фильтром, выделен красным цветом.
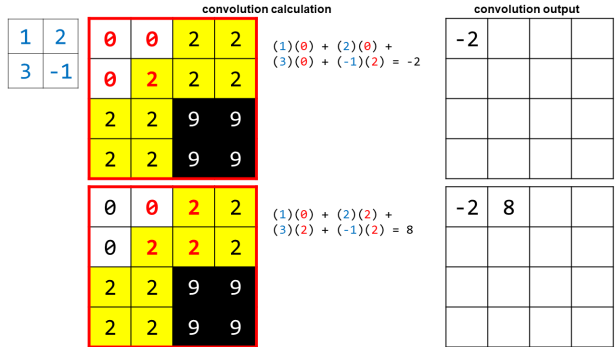
- Вычисление в середине показывает операцию свертки, где мы сопоставляем элементы фильтра с элементами изображения, перемножаем соответствующие числа, а затем суммируем их, чтобы получить результат свертки.
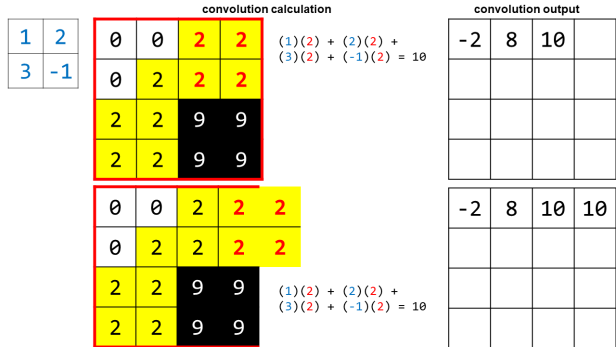
В последней части вы можете видеть, что для получения последнего значения свертки фильтр выскользнул из нашей исходной области. Я показываю это, потому что на практике мы применяем свертку ко всему изображению, поэтому за небольшой областью, на которой мы сфокусировались для примера, все еще существуют реальные пиксели. Однако, рассматривая изображение в целом, мы в конечном итоге достигнем «реального края» с нашим фильтром, и нам придется остановиться. Это означает, что вывод нашей свертки будет немного меньше исходного изображения.
Вот выход свертки для красной области и фильтра, который мы выбрали:
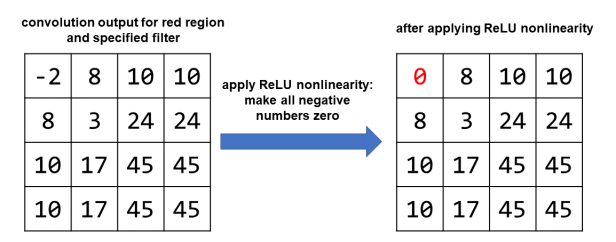
Функция активации
Как только мы закончим выполнение свертки, мы применяем «нелинейность». Это нелинейная функция, которое позволяет CNN изучать более сложные шаблоны в целом. Одной из популярных функций активации является ReLU, или «выпрямленная линейная единица». Звучит причудливо, но на самом деле просто: вы заменяете каждое отрицательное значение на ноль.
Объединение в пул
Последний шаг – объединение (пулинг). Этот шаг приводит к уменьшению размера представления. Обычно мы выбираем окно пула того же размера, что и фильтр. Мы выбрали фильтр 2 × 2, поэтому мы выбираем окно пула также 2 × 2.
Здесь мы выполним «максимальное объединение», где мы выбираем наибольшее значение в каждом окне объединения.
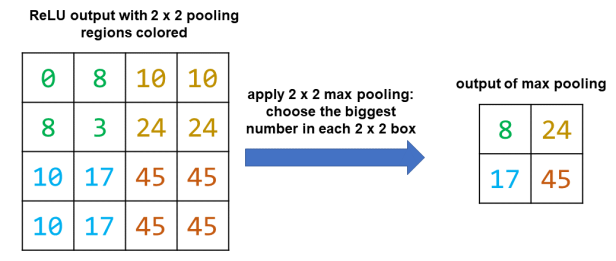
Также возможно выполнить другие виды объединения в пул, такие как усреднение пула, где вместо максимума мы взяли бы среднее значение всех значений в окне пула. Объединение в пул полезно, потому что оно уменьшает размер представления, тем самым уменьшая объем вычислений, требуемый в целом.
В одном сверточном слое содержится много фильтров
В приведенном выше примере мы применили свертку, нелинейность и объединение, чтобы перейти от квадрата 4 x 4 пикселей к представлению 2 x 2, сосредоточив внимание только на одном фильтре. Однако в действительности один сверточный слой использует много разных фильтров, все одного размера, но с разными значениями.
Допустим, в нашем первом сверточном слое мы применяем 32 разных фильтра, каждый из которых имеет размер 2 x 2. Тогда общий выходной размер для всего слоя составляет 2 x 2 x 32. Каждый фильтр обнаруживает различные аспекты изображения, потому что каждый фильтр содержит разные значения.
В CNN есть много слоев
Мы не останавливаемся, когда у нас есть представление 2 x 2 x 32. Вместо этого мы можем сделать еще один раунд свертки, нелинейности и объединения – на этот раз применяя операции к представлению 2 x 2 x 32 вместо исходного изображения. Этот второй раунд является вторым «сверточным слоем». Современный CNN может иметь 8 или 99 слоев, или любое количество слоев, которое выберет разработчик.
Основная идея CNN с несколькими слоями состоит в том, что фильтры в нижних слоях (ближе к входному изображению) будут изучать простые характеристики, например, где находятся края, а фильтры в верхних слоях (более абстрактные) будут изучать сложные характеристики, например, как человеческие лица выглядят на фотографиях или как выглядит пневмония на рентгенограмме.
Визуализация сверточных фильтров
Существуют разные способы визуализации того, что видит CNN, с помощью разных фильтров. На рисунке 1 этой статьи показано, как выглядят фильтры первого уровня сети CNN под названием AlexNet при взгляде на изображение кота. Эта статья и эта статья приводят дополнительные фильтры визуализации. Видео «Deep Visualization Toolbox» от Jason Yosinski, безусловно, стоит посмотреть, чтобы лучше понять, как CNN объединяют простые функции (например, края) из нижних уровней для обнаружения сложных объектов (таких как лица или книги) с фильтрами верхних уровней.
Выводы
CNN являются мощной структурой для распознавания изображений и предполагают многократное применение простых операций на многих уровнях. Они широко используются в промышленности и в научных кругах и уже начали оказывать влияние на области медицины, основанные на изображениях, включая радиологию, дерматологию и патологию.
Представленное изображение
Показанное изображение – «Мона Лиза» Леонардо да Винчи, которую я позаимствовала для примера «классификации эмоций» (по иронии, поскольку люди не согласны с тем, какие эмоции выражает Мона Лиза, а также потому, что я слушала биографию Ленардо да Винчи в машине.) Вот несколько забавных фактов о Моне Лизе:
- У Моны Лизы были брови и ресницы, но они, вероятно, были удалены случайно, когда реставратор чистил глаза Моны Лизы.
- Isleworth Mona Lisa считается более ранней версией Mona Lisa Леонардо да Винчи, изображающей ту же картину. Это более широкая картина, чем знаменитая Мона Лиза, и включает колонны по обе стороны от изображения.
- Мона Лиза в настоящее время имеет желтовато-коричневый оттенок. Тем не менее, различные исследования показывают, что раньше Мона Лиза имела гораздо более яркие цвета с ярко-красными и синими оттенками. У нее также, вероятно, есть шуба на коленях.
Дополнительные ссылки:
За последние несколько лет я составила список особо полезных ресурсов, связанных с CNN. Вот они!
- “Convolutional Neural Networks (CNNs): An Illustrated Explanation” is an excellent blog post from the Association for Computing Machinery (ACM) providing details on CNN design and implementation.
- “A Beginner’s Guide to Understanding Convolutional Neural Networks” is another great post, particularly the section that uses a drawing of a mouse to explain how CNN filters work.
- Convolutional Neural Networks (CNNs / ConvNets): this article is from a Stanford course, CS 231n.
- vdumoulin/conv_arithmetic on Github contains awesome animations showing how different kinds of convolutional filters are applied to images. It includes some “fancy convolution” techniques like transposed convolution and dilated convolution. For more information on dilated convolution, check out “Understanding 2D Dilated Convolution Operation with Examples in Numpy and Tensorflow with Interactive Code”
- Chapter 9 of the Deep Learning book by Aaron C. Courville, Ian Goodfellow, and Yoshua Bengio, provides a more technical discussion of CNNs.
- Hvass-Labs/TensorFlow-Tutorials/02_Convolutional_Neural_Network.ipynb is a Python notebook with Tensorflow code for a CNN that solves the MNIST handwritten digits classification task.
- This paper, On Deep Learning for Medical Image Analysis (JAMA Guide to Statistics and Methods, 2018), is an overview of CNNs written for medical professionals. It also contains a great video explanation of CNNs. This article is behind a paywall, so if you are at a university you will have to log in to your university’s library resources to access it.
Первоначально опубликовано на http://glassboxmedicine.com 5 мая, 2019.