Адаптированный перевод прекрасной статьи энтузиаста технологий машинного обучения Javaid Nabi.

Чтобы понимать как алгоритм машинного обучения учится предсказывать результаты на основе данных, важно разобраться в основных концепциях и понятиях, используемых при обучении алгоритма.
Функции оценки
В контексте технологии машинного обучения, оценка – это статистический термин для нахождения некоторого приближения неизвестного параметра на основе некоторых данных. Точечная оценка – это попытка найти единственное лучшее приближение некоторого количества интересующих нас параметров. Или на более формальном языке математической статистики — точечная оценка это число, оцениваемое на основе наблюдений, предположительно близкое к оцениваемому параметру.
Под количеством
интересующих параметров обычно подразумевается:
• Один параметр
• Вектор параметров – например, веса в линейной
регрессии
• Целая функция
Точечная оценка
Чтобы отличать оценки параметров от их истинного значения, представим точечную оценку параметра θ как θˆ. Пусть {x(1), x(2), .. x(m)} будут m независимыми и одинаково распределенными величинами. Тогда точечная оценка может быть записана как некоторая функция этих величин:
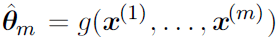
Такое определение точечной оценки является очень общим и предоставляет разработчику большую свободу действий. Почти любая функция, таким образом, может рассматриваться как оценщик, но хороший оценщик – это функция, значения которой близки к истинному базовому значению θ, которое сгенерированно обучающими данными.
Точечная оценка также может относиться к оценке взаимосвязи между входными и целевыми переменными, в этом случае чаще называемой функцией оценки.
Функция оценки
Задача, решаемая машинным обучением, заключается в попытке предсказать переменную y по заданному входному вектору x. Мы предполагаем, что существует функция f(x), которая описывает приблизительную связь между y и x. Например, можно предположить, что y = f(x) + ε, где ε обозначает часть y, которая явно не предсказывается входным вектором x. При оценке функций нас интересует приближение f с помощью модели или оценки fˆ. Функция оценки в действительности это тоже самое, что оценка параметра θ; функция оценки f это просто точечная оценка в функциональном пространстве. Пример: в полиномиальной регрессии мы либо оцениваем параметр w, либо оцениваем функцию отображения из x в y.
Смещение и дисперсия
Смещение и дисперсия измеряют два разных источника ошибки функции оценки. Смещение измеряет ожидаемое отклонение от истинного значения функции или параметра. Дисперсия, с другой стороны, показывает меру отклонения от ожидаемого значения оценки, которую может вызвать любая конкретная выборка данных.
Смещение
Смещение определяется следующим образом:
где ожидаемое значение E(θˆm) для данных (рассматриваемых как выборки из случайной величины) и θ является истинным базовым значением, используемым для определения распределения, генерирующего данные.

Оценщик θˆm называется несмещенным, если bias(θˆm)=0, что подразумевает что E(θˆm) = θ.
Дисперсия и Стандартная ошибка
Дисперсия оценки обозначается как Var(θˆ), где случайная величина является обучающим множеством. Альтернативно, квадратный корень дисперсии называется стандартной ошибкой, обозначаемой как SE(θˆ). Дисперсия или стандартная ошибка оценщика показывает меру ожидания того, как оценка, которую мы вычисляем, будет изменяться по мере того, как мы меняем выборки из базового набора данных, генерирующих процесс.
Точно так же, как мы хотели бы, чтобы функция оценки имела малое смещение, мы также стремимся, чтобы у нее была относительно низкая дисперсия.
Давайте теперь рассмотрим некоторые обычно используемые функции оценки.
Оценка Максимального Правдоподобия (MLE)
Оценка максимального правдоподобия может быть определена как метод оценки параметров (таких как среднее значение или дисперсия) из выборки данных, так что вероятность получения наблюдаемых данных максимальна.
Рассмотрим набор из m примеров X={x(1),… , x(m)} взятых независимо из неизвестного набора данных, генерирующих распределение Pdata(x). Пусть Pmodel(x;θ) – параметрическое семейство распределений вероятностей над тем же пространством, индексированное параметром θ. Другими словами, Pmodel(x;θ) отображает любую конфигурацию x в значение, оценивающее истинную вероятность Pdata(x).
Оценка максимального правдоподобия для θ определяется как:

Поскольку мы предположили, что примеры являются независимыми выборками, приведенное выше уравнение можно записать в виде:
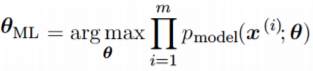
Эта произведение многих вероятностей может быть неудобным по ряду причин. В частности, оно склонно к числовой недооценке. Кроме того, чтобы найти максимумы/минимумы этой функции, мы должны взять производную этой функции от θ и приравнять ее к 0. Поскольку это произведение членов, нам нужно применить правило цепочки, которое довольно громоздко. Чтобы получить более удобную, но эквивалентную задачу оптимизации, можно использовать логарифм вероятности, который не меняет его argmax, но удобно превращает произведение в сумму, и поскольку логарифм – строго возрастающая функция (функция натурального логарифма – монотонное преобразование), это не повлияет на итоговое значение θ.
В итоге, получаем:

Два важных свойства: сходимость и эффективность
Сходимость. По мере того, как число обучающих выборок приближается к бесконечности, оценка максимального правдоподобия сходится к истинному значению параметра.
Эффективность. Способ измерения того, насколько мы близки к истинному параметру, – это ожидаемая средняя квадратичная ошибка, вычисление квадратичной разницы между оценочными и истинными значениями параметров, где математическое ожидание вычисляется над m обучающими выборками из данных, генерирующих распределение. Эта параметрическая среднеквадратичная ошибка уменьшается с увеличением m, и для больших m нижняя граница неравенства Крамера-Рао показывает, что ни у одной сходящейся функции оценки нет среднеквадратичной ошибки меньше, чем у оценки максимального правдоподобия.
Именно по причине сходимости и эффективности, оценка максимального правдоподобия часто считается предпочтительным оценщиком для машинного обучения.
Когда количество примеров достаточно мало, чтобы привести к переобучению, стратегии регуляризации, такие как понижающие веса, могут использоваться для получения смещенной версии оценки максимального правдоподобия, которая имеет меньшую дисперсию, когда данные обучения ограничены.
Максимальная апостериорная (MAP) оценка
Согласно байесовскому подходу, можно учесть влияние предварительных данных на выбор точечной оценки. MAP может использоваться для получения точечной оценки ненаблюдаемой величины на основе эмпирических данных. Оценка MAP выбирает точку максимальной апостериорной вероятности (или максимальной плотности вероятности в более распространенном случае непрерывного θ):

где с правой стороны, log(p(x|θ)) – стандартный член логарифмической вероятности и log(p(θ)) соответствует изначальному распределению.
Как и при полном байесовском методе, байесовский MAP имеет преимущество
использования изначальной информации, которой нет
в обучающих данных. Эта дополнительная информация помогает уменьшить дисперсию
для точечной оценки MAP (по сравнению с оценкой MLE). Однако, это происходит ценой повышенного смещения.
Функции потерь
В большинстве обучающих сетей ошибка рассчитывается как разница между фактическим выходным значением y и прогнозируемым выходным значением ŷ. Функция, используемая для вычисления этой ошибки, известна как функция потерь, также часто называемая функцией ошибки или затрат.
До сих пор наше основное внимание уделялось оценке параметров с помощью MLE или MAP. Причина, по которой мы обсуждали это раньше, заключается в том, что и MLE, и MAP предоставляют механизм для получения функции потерь.
Давайте рассмотрим некоторые часто используемые функции потерь.
Средняя квадратичная ошибка (MSE): средняя квадратичная ошибка является наиболее распространенной функцией потерь. Функция потерь MSE широко используется в линейной регрессии в качестве показателя эффективности. Чтобы рассчитать MSE, надо взять разницу между предсказанными значениями и истинными, возвести ее в квадрат и усреднить по всему набору данных.

где y(i) – фактический ожидаемый результат, а ŷ(i) – прогноз модели.
Многие функции потерь (затрат), используемые в машинном обучении, включая MSE, могут быть получены из метода максимального правдоподобия.
Чтобы увидеть, как мы можем вывести функции потерь из MLE или MAP, требуется некоторая математика. Вы можете пропустить ее и перейти к следующему разделу.
Получение MSE из MLE
Алгоритм линейной регрессии учится принимать входные данные x и получать выходные значения ŷ. Отображение x в ŷ делается так, чтобы минимизировать среднеквадратичную ошибку. Но как мы выбрали MSE в качестве критерия для линейной регрессии? Придем к этому решению с точки зрения оценки максимального правдоподобия. Вместо того, чтобы производить одно предсказание ŷ , давайте рассмотрим модель условного распределения p(y|x).
Можно смоделировать модель линейной регрессии следующим образом:

мы предполагаем, что у имеет нормальное распределение с ŷ в качестве среднего значения распределения и некоторой постоянной σ² в качестве дисперсии, выбранной пользователем. Нормальное распределения являются разумным выбором во многих случаях. В отсутствие предварительных данных о том, какое распределение в действительности соответствует рассматриваемым данным, нормальное распределение является хорошим выбором по умолчанию.
Вернемся к логарифмической вероятности, определенной ранее:

где ŷ(i) – результат линейной регрессии на i-м входе, а m – количество обучающих примеров. Мы видим, что две первые величины являются постоянными, поэтому максимизация логарифмической вероятности сводится к минимизации MSE:
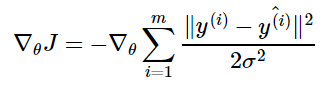
Таким образом, максимизация логарифмического правдоподобия относительно θ дает такую же оценку параметров θ, что и минимизация среднеквадратичной ошибки. Два критерия имеют разные значения, но одинаковое расположение оптимума. Это оправдывает использование MSE в качестве функции оценки максимального правдоподобия.
Кросс-энтропия (или логарифмическая функция потерь – log loss): Кросс-энтропия измеряет расхождение между двумя вероятностными распределениями. Если кросс-энтропия велика, это означает, что разница между двумя распределениями велика, а если кросс-энтропия мала, то распределения похожи друг на друга.
Кросс-энтропия определяется как:

где P – распределение истинных ответов, а Q – распределение вероятностей прогнозов модели. Можно показать, что функция кросс-энтропии также получается из MLE, но я не буду утомлять вас большим количеством математики.
Давайте еще
упростим это для нашей модели с:
• N – количество наблюдений
• M – количество возможных меток класса (собака,
кошка, рыба)
• y – двоичный индикатор (0 или 1) того, является
ли метка класса C правильной классификацией для наблюдения O
• p – прогнозируемая вероятность модели
Бинарная классификация
В случае бинарной классификации (M=2), формула имеет вид:

При двоичной классификации каждая предсказанная вероятность сравнивается с фактическим значением класса (0 или 1), и вычисляется оценка, которая штрафует вероятность на основе расстояния от ожидаемого значения.
Визуализация
На приведенном ниже графике показан диапазон возможных значений логистической функции потерь с учетом истинного наблюдения (y = 1). Когда прогнозируемая вероятность приближается к 1, логистическая функция потерь медленно уменьшается. Однако при уменьшении прогнозируемой вероятности она быстро возрастает.
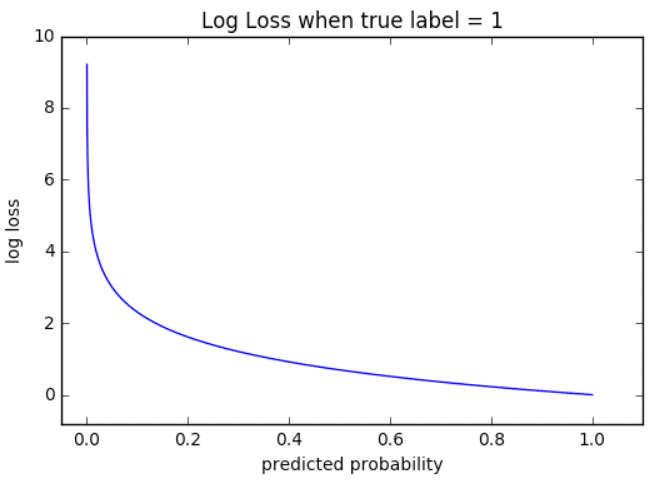
Логистическая функция потерь наказывает оба типа ошибок, но особенно те прогнозы, которые являются достоверными и ошибочными!
Мульти-классовая классификация
В случае мульти-классовой классификации (M>2) мы берем сумму значений логарифмических функций потерь для каждого прогноза наблюдаемых классов.
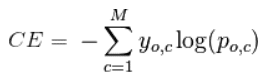
Кросс-энтропия для бинарной или двух-классовой задачи прогнозирования фактически рассчитывается как средняя кросс-энтропия среди всех примеров. Log loss использует отрицательные значения логарифма, чтобы обеспечить удобную метрику для сравнения. Этот подход основан на том, что логарифм чисел <1 возвращает отрицательные значения, что затрудняет работу при сравнении производительности двух моделей. Вы можете почитать эту статью, где детально обсуждается функция кросс-энтропии потерь.
Задачи ML и соответствующие функции потерь
Давайте посмотрим, какие обычно используются выходные слои и функции потерь в задачах машинного обучения:
Задача регрессии
Задача, когда вы прогнозируете вещественное число.
• Конфигурация выходного уровня: один
узел с линейной единицей активации.
• Функция
потерь: средняя квадратическая ошибка (MSE).

Задача бинарной классификации
Задача состоит в том, чтобы классифицировать пример как принадлежащий одному из двух классов. Или более точно, задача сформулирована как предсказание вероятности того, что пример принадлежит первому классу, например, классу, которому вы присваиваете целочисленное значение 1, тогда как другому классу присваивается значение 0.
• Конфигурация выходного
уровня: один узел с сигмовидной активационной функцией.
• Функция
потерь: кросс-энтропия, также называемая логарифмической функцией потерь.
Задача мульти-классовой классификации
Эта задача состоит в том, чтобы классифицировать пример как принадлежащий одному из нескольких классов. Задача сформулирована как предсказание вероятности того, что пример принадлежит каждому классу.
• Конфигурация выходного уровня: один
узел для каждого класса, использующий функцию активации softmax.
• Функция потерь: кросс-энтропия, также называемая логарифмической функцией потерь.

Рассмотрев оценку и различные функции потерь, давайте перейдем к роли оптимизаторов в алгоритмах ML.
Оптимизаторы
Чтобы свести к минимуму ошибку или потерю в прогнозировании, модель, используя примеры из обучающей выборки, обновляет параметры модели W. Расчеты ошибок строятся в зависимости от W и также описываются графиком функции затрат J(w), поскольку она определяет затраты/наказание модели. Таким образом, минимизация ошибки также часто называется минимизацией функции затрат.
Но как именно это делается? Используя оптимизаторы.
Оптимизаторы используются для обновления весов и смещений, то есть внутренних параметров модели, чтобы уменьшить ошибку.
Самым важным методом и основой того, как мы обучаем и оптимизируем нашу модель, является метод Градиентного Спуска.
Градиентный Спуск
Когда мы строим функцию затрат J(w), это можно представить следующим образом:
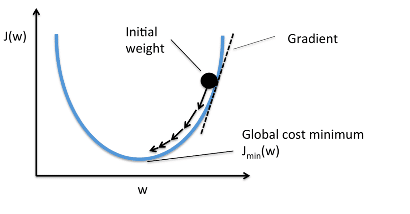
Как видно из кривой, существует значение параметров W, которое имеет минимальное значение Jmin. Нам нужно найти способ достичь этого минимального значения.
В алгоритме градиентного спуска мы начинаем со случайных параметров модели и вычисляем ошибку для каждой итерации обучения, продолжая обновлять параметры, чтобы приблизиться к минимальным значениям.
Повторяем до достижения минимума:
{

}
В приведенном выше уравнении мы обновляем параметры модели после каждой итерации. Второй член уравнения вычисляет наклон или градиент кривой на каждой итерации.
Градиент функции затрат вычисляется как частная производная функции затрат J по каждому параметру модели Wj, где j принимает значение числа признаков [1, n]. α – альфа, это скорость обучения, определяющий как быстро мы хотим двигаться к минимуму. Если α слишком велико, мы можем проскочить минимум. Если α слишком мало, это приведет к небольшим этапам обучения, поэтому общее время, затрачиваемое моделью для достижения минимума, будет больше.
Есть три способа сделать градиентный спуск:
Пакетный градиентный спуск: использует все обучающие данные для обновления параметров модели в каждой итерации.
Мини-пакетный градиентный спуск: вместо использования всех данных, мини-пакетный градиентный спуск делит тренировочный набор на меньший размер, называемый партией, и обозначаемый буквой «b». Таким образом, мини-пакет «b» используется для обновления параметров модели на каждой итерации.
Вот некоторые другие часто используемые Оптимизаторы:
Стохастический Градиентный Спуск (SGD): обновляет параметры, используя только один обучающий параметр на каждой итерации. Такой параметр обычно выбирается случайным образом. Стохастический градиентный спуск часто предпочтителен для оптимизации функций затрат, когда есть сотни тысяч обучающих или более параметров, поскольку он будет сходиться быстрее, чем пакетный градиентный спуск.
Адаград
Адаград адаптирует скорость обучения конкретно к индивидуальным особенностям: это означает, что некоторые веса в вашем наборе данных будут отличаться от других. Это работает очень хорошо для разреженных наборов данных, где пропущено много входных значений. Однако, у Адаграда есть одна серьезная проблема: адаптивная скорость обучения со временем становится очень маленькой.
Некоторые другие оптимизаторы, описанные ниже, пытаются справиться с этой проблемой.
RMSprop
RMSprop – это специальная версия Adagrad, разработанная профессором Джеффри Хинтоном в его классе нейронных сетей. Вместо того, чтобы вычислять все градиенты, он вычисляет градиенты только в фиксированном окне. RMSprop похож на Adaprop, это еще один оптимизатор, который пытается решить некоторые проблемы, которые Адаград оставляет открытыми.
Адам
Адам означает адаптивную оценку момента и является еще одним способом использования предыдущих градиентов для вычисления текущих градиентов. Адам также использует концепцию импульса, добавляя доли предыдущих градиентов к текущему. Этот оптимизатор получил довольно широкое распространение и практически принят для использования в обучающих нейронных сетях.
Вы только что ознакомились с кратким обзором оптимизаторов. Более подробно об этом можно прочитать здесь.
Я надеюсь, что после прочтения этой статьи, вы будете лучше понимать что происходит, когда Вы пишите следующий код:
# loss function: Binary Cross-entropy and optimizer: Adam
model.compile(loss='binary_crossentropy', optimizer='adam')или
# loss function: MSE and optimizer: stochastic gradient descent
model.compile(loss='mean_squared_error', optimizer='sgd')Спасибо за проявленный интерес!
Ссылки:
[1] https://www.deeplearningbook.org/contents/ml.html
[3] https://blog.algorithmia.com/introduction-to-optimizers/
[4] https://jhui.github.io/2017/01/05/Deep-learning-Information-theory/
[5] https://blog.algorithmia.com/introduction-to-loss-functions/
[6] https://gombru.github.io/2018/05/23/cross_entropy_loss/
[7] https://www.kdnuggets.com/2018/04/right-metric-evaluating-machine-learning-models-1.html